医学统计常用方法集合
01 两组间均数t检验
示例:比较两组所代表的总体疾病组、健康组血小板含量,经过比较,两组差异有明显统计学意义。可以提示该疾病可以引起血小板明显升高(注:数据为示例数据)。
用途:两组间均数比较常用于比较两组指标上的差异,用于发现影响因素、差异来源等。
可用统计软件:Stata、R、SAS、SPSS等。示例图片:Prism 5.0。


图1 健康组与病例组血小板含量比较
02 两两相关
示例:详见下图所示。B指标与Rating之间存在正相关、A指标与血小板之间呈现正相关(注:数据为示例数据)。
用途:用于验证、发现、探讨两指标的共变关系。
可用统计软件:Stata、R、SAS、SPSS等。示例图片:Prism 5.0。

图2 等级Rating与B value之间呈现正相关

图3 A指标与血小板之间呈现正相关
03 路径分析
示例:某种疾病住院费用影响因素的路径图。
用途:探讨、验证多因素模型下影响某结局的交互模型,前提需要有一定的理论假设。
可用统计软件:AMOS。示例图片:AMOS。
.png")
图4 住院费用的路径分析(注:数据为示例数据)
04 二分类Logistic回归
示例:某疾病是否发病受A、B、C三种因素因素,A因素为高危因素 (95%CI为 2.476~7.486) >1,B因素为保护因素;C因素为混杂因素(注:数据为示例数据)。
用途:用于探讨影响某二分类(如死亡或生存、生病或健康等)结局发生的影响因素,及影响力大小。
可用统计软件:Stata、R、SAS、SPSS等。

05 决策树模型
示例:某人群是否再次发生骨折的高危因素决策树模型。(注:数据为示例数据)
用途:与路径分析相似,以倒推的方式展示结局发生的影响因素来源及大小。
可用统计软件:Stata、R、SAS、SPSS等。示例图片:Microsofter visio 2007。

图5 决策树模型
06 ROC分析
示例:三种筛查方法的受试者曲线,曲线下面积越高,说明判别效果越佳(注:数据为示例数据)。
用途:用于筛选生物学标志物、临床预测指标等。
可用统计软件:Stata、R、SAS、SPSS等。示例图片:SPSS 21.0。

图6 示例ROC曲线
07 时间序列
示例:某传染病随时间变化趋势及时间预测模型建立。(注:数据为示例数据)。
用途:探讨事件随时间变化规律,为预测提供支持。
可用统计软件:Stata、R、SAS、SPSS等。示例图片:SPSS 21.0。

图7 救命时间序列模型
08 生存曲线
示例:两组治疗方法下的患者的生存曲线。图中所示放化疗结合患者的生存时间明显要长于单独做化疗者(注:数据为示例数据)。
用途:用于比较两种治疗方法、干预后段之间主要效应差异(不一定是死亡、存活)。可用于比较并发症的发生、感染的发生等。
可用统计软件:Stata、R、SAS、SPSS等。示例图片:SPSS 21.0。

图8 救命生存曲线
09 GIS地图信息分析
示例:乌鲁木齐市某病发病例数分布图。(注:数据为示例数据)。
用途:事件的空间分布特点,用于探讨病例的空间集中特点,流行病学中应用较多。
可用统计软件:Mapinfo, Arc GIS等。示例图片:Mapinfo professional 9.5。

图9 如乌鲁木齐市某病发病数地区分布图
10 Meta分析
示例:11项研究合并表明某暴露是某事件发生的危险因素OR=2.19(95% CI=1.60-3.01)。
用途:基于循证医学理念,汇总医学已有文献研究结果,扩大研究效能,可用作于课题前期提供线索及探索。
可用统计软件:Rev Man,Stata等。示例图片:Rev Man 5.0。

图10 Meta分析结果汇总
11 关联分析
示例:选择使用arules软件包中的Groceries数据集,该数据集是某一食品杂货店一个月的真实交易数据,通过做关联分析,发掘消费者对于这些商品的购买行为之间是否有关联性,以及关联性有多强,并将获取的信息付诸于实际运用。(注:数据为示例数据)。
用途:目的是从大量数据中发现项集之间的有趣关联或相互关系。
可用统计软件:Stata、R、SAS、SPSS等。示例图片:R studio。

图11 关联规则分组图
12 聚类分析
示例:随机创建三个簇点,利用rnorm()函数。
用途:目的是把若干事物按照某种标准归为几个类别,其中较为相近的聚为一类,不那么相近的聚于不同类。
可用统计软件:Stata、R、SAS、SPSS等。示例图片:R studio。

图12 聚类K=3的分类图
13 判别分析
示例:选用kknn软件包中的miete数据集进行算法演示,该数据集记录了1994年慕尼黑的住房租金标准中的一些有趣变了,比如房子的面积,是否有浴室,是否有中央供暖,是否供应热水等,都会影响租金。
用途:目的是判断样本所属的类别,其依据是那些已知类别样本的属性信息。
可用统计软件:Stata、R、SAS、SPSS等。示例图片:R studio。

图13 判别规则图
14 随机森林
示例:选用自带的数据集mtcars进行示例,mtcars是美国Motor Trend 杂志收集的32辆汽车的10项指标,对给定的饿自变量数据进行分类和预测。
用途:目的是基于决策树的分类器集成算法,其中每一颗树都依赖于一个随机变量,森林中的所有的向量都是独立同分布的,它可以很好的预测多达几千个解释变量的作用。
可用统计软件:Stata、R、SAS、SPSS等。示例图片:R studio。

图14 变量重要性图
15 支持向量机
示例:选用datasets软件包中的iris数据集进行算法演示。
用途:它是建立在统计学理论的VC维理论和结构风险小原理基础之上,根据有限样本在模型的复杂性和学习能力之间寻求佳折中,以期望获得好的推广能力。其中模型的复杂性只对特定训练样本的学习精度,学习能力是指无错误的识别任意样本的能力。
可用统计软件:Stata、R、SAS、SPSS等。示例图片:R studio。

图15 在维度Width和Length下各类别分布图
16 神经网络
示例:选用datasets软件包中的iris数据集进行算法演示。
用途:它是一种运算模型,由大量的节点和之间的相互连接构成。它是一种非程序化、适应性、大脑风格的信息处理,其本质是通过网络的变换和动力学行为得到一种并行分部的信息处理功能,并子啊不同程度和层次上模仿人脑神经系统的信息处理功能。
可用统计软件:Stata、R、SAS、SPSS等。示例图片:R studio。

图16 在不同隐藏层节点数下模型的误判率图
相关阅读推荐:
 打开微信“扫一扫”,打开网页后点击屏幕右上角分享按钮
打开微信“扫一扫”,打开网页后点击屏幕右上角分享按钮

-
论文打印要求是什么,单面还是双面? 132340
-
 ieee论文什么水平,含金量如何? 71501
ieee论文什么水平,含金量如何? 71501
-
河南一类目录期刊 2019.08.02 17:12
-
核心期刊发表论文价格 2019.08.02 15:58
-
中文核心和北大核心有何区别? 2019.08.02 15:13
-
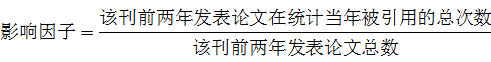 常用评价期刊的指标有那些? 2019.08.02 14:19
常用评价期刊的指标有那些? 2019.08.02 14:19
-
 单变量方差分析之spss实现步骤
单变量方差分析之spss实现步骤 -
 如何用SPSS处理1:N匹配的病例对照研究资料
如何用SPSS处理1:N匹配的病例对照研究资料 -
 配对卡方检验与一致性检验的SPSS操作步骤
配对卡方检验与一致性检验的SPSS操作步骤
